
マーケターのための「機械学習」活用の基礎知識 -
機械学習とは、コンピュータがデータからパターンやルールを自律的に学習し、識別や予測を行う技術です。
AI(人工知能)の進化を支える中核技術であり、特に「ディープラーニング(深層学習)」の登場により、画像認識や自然言語処理の精度が飛躍的に向上しました。
本記事では、機械学習の学習プロセスから、教師あり・教師なし学習の違い、そしてマーケティング活用を阻む「データ整備」の重要性まで、実務的な視点で徹底解説します。
そもそも機械学習とは?
「機械学習」とは、データを使って機械(コンピュータ)に学ばせて、ヒトに近い知的な判断をさせる手法、ないしは技術です。
総務省では、機械学習を、ヒトの学習に近い仕組みをコンピュータで実現する仕組みであり、一定の計算方法(アルゴリズム)にもとづいて、入力されたデータからパターンやルールを見出し、そのパターンやルールと新たに入力されたデータとをマッチングすることで、データに関する識別や予測などを可能にする手法であると定義しています。
表1. そもそも機械学習とは?
| トピック | 内容と定義 |
|---|---|
| 機械学習の定義 | データを用いてコンピュータに学ばせ、人間のような知的判断を実現する技術。特定のアルゴリズムに基づき、データからパターンやルールを抽出する。 |
| AI・深層学習との関係 | AIは広義の人工知能、機械学習はAIを実現する手法、ディープラーニング(深層学習)はニューラルネットワークを用いた機械学習の一種である。 |
| ディープラーニングの革新性 | 人間が指定しなくても、コンピュータがデータから自動的に「特徴量」を抽出できる点。翻訳や将棋AIなどで高い精度を発揮する。 |
この機械学習について語られるとき「機械学習はAI(人工知能)なのか」という議論がよく行われますが、そもそもAIとは何かについての明確な回答は存在しません。理由は単純で、ヒトの「叡智」「知」とは何かの決まった定義がないからです。ゆえに「機械学習はAIなのか」の議論にも正解はなく、現状では「機械学習はAIを実現する手法の一つ」というのが世の中のコンセンサスになっています。
AIの飛躍的な進歩をもたらしたとされる「ディープラーニング(深層学習)」は機械学習の一種です。総務省では、ディープラーニングと機械学習、そしてAIの位置関係を図1のように表現しています。
図1:AI、機械学習、ディープラーニングとの関係
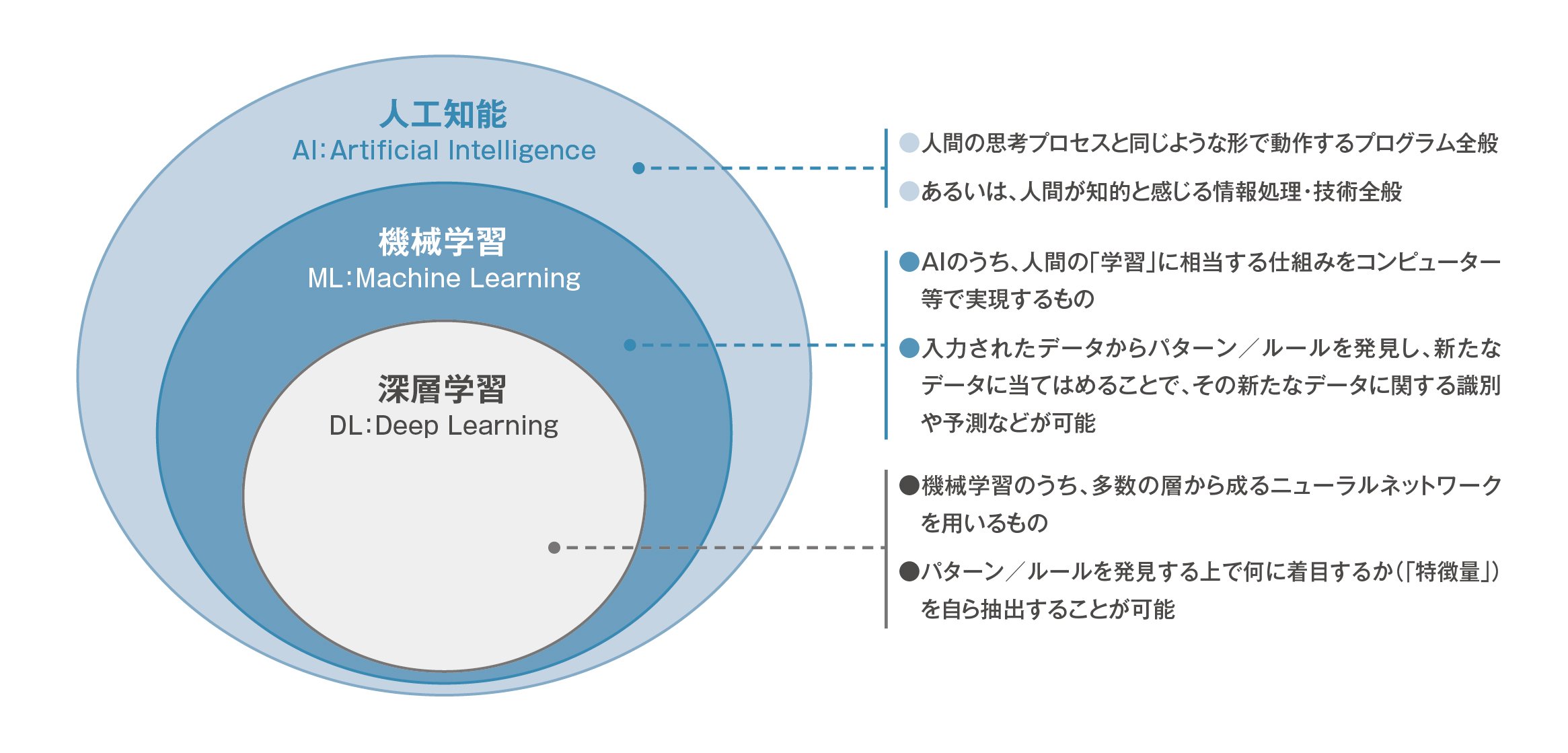
出典:総務省『令和元年版 情報通信白書』
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r01/html/nb000000.html
図1にある通り、ディープラーニングはニューラルネットワークを用いて行う機械学習のことです。この機械学習が“画期的”とされている最大の理由は、データの学習によって、データのパターンやルールを見出すために必要な特異点(正式には「特微量」と呼ばれる)をコンピュータが自動で抽出することです。
例えば「ネコ」を認識するAIを機械学習によって実現しようとした場合、ネコを他から区別するためにどこに注目すべきかの特微量を人間が指定した上で、コンピュータにネコの画像を学習させる必要がありました。
一方、ディープラーニングでは、ネコの画像を(これはネコであるという情報を付加して)数多く学習させるだけで、コンピュータが自動的に特微量を抽出してネコを認識できるようになるとされています。
そのため、ディープラーニングでは、例えば、英日・日英の翻訳を自動化するAIの開発においても、日本語と英訳のペアを大量に学習させるだけで、精度の高い翻訳を行うAIが実現されたり、棋譜の大量の学習によって将棋のプロにも勝利できるようなAIが実現されたりします。
機械学習を活用するための基礎
機械学習における「学習」と「推論」のプロセス
ディープラーニングも含めて、機械学習の基本はデータをAIの開発に生かすということです。そのデータの使い方を理解する上では、機械学習における学習プロセスがどのようなものであるかを知っておくことが大切です。
総務省の『AIネットワーク社会推進会議AI経済検討会 報告書』によると、機械学習のプロセスは大きく二つに分けて捉えることができるといいます。一つは、「学習」のプロセスであり、もう一つは、推論用データをもとに実際の業務・サービスに活用する「推論」のプロセスです(図2)。
図2:機械学習のプロセス
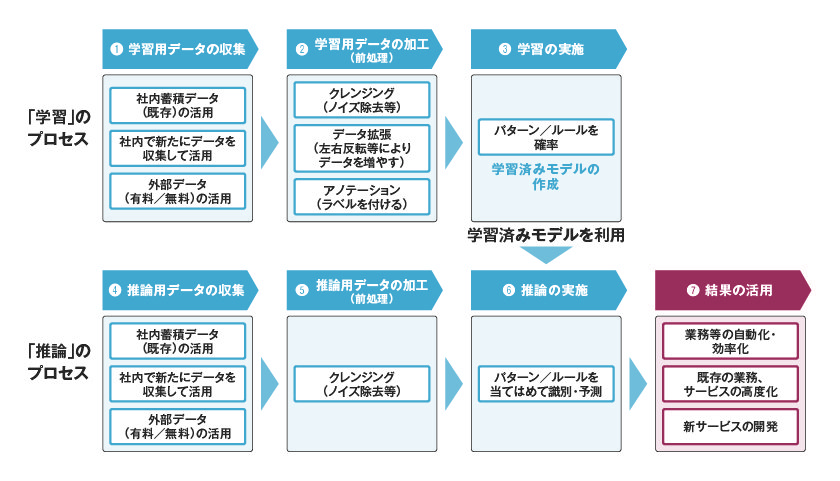 出所:AI ネットワーク社会推進会議AI 経済検討会
出所:AI ネットワーク社会推進会議AI 経済検討会
https://www.soumu.go.jp/main_content/000622906.pdf
図2にある通り、学習のプロセスは、入力されたデータをもとにコンピュータが識別を行うためのパターンを確立するプロセスです。このプロセスで確立されたパターンは「学習済みモデル」と呼ばれます。また、推論のプロセスは、学習済みモデルに対してデータ(推論用データ)を入力して、実際にそのデータの識別などを行うプロセスです。
精度向上に欠かせない「学習データ」の質
ここで留意すべき点は、推論の精度を高める上では、推論用データに近い性質のデータを学習用データとして用意して、コンピュータに学習させたほうが良いという点です。
例えば、ベルトコンベアの上を流れる製品の動画像から、キズのある不良品をリアルタイムに検出するAIを開発するとしましょう。
この場合、学習のプロセスでは「キズのある製品」の画像を学習させることになりますが、その画像は「ベルトコンベア上を流れる、キズのある製品」の画像に近いものでないと、学習済みモデルを使った推論の精度はなかなか上げられないことになります。
このように、機械学習では、AIに対して実際にどのようなデータをインプットして、どのような結果を得たいかによって、学習用に自社独自のデータを数多く用意しなければならなくなる場合があります。
機械学習の3つの手法とその特徴
機械学習の活用を図るうえでは、学習法の違いによって、用途にも違いが出ることも理解しておく必要があります。具体的には、機械学習の方法には大きく「教師あり学習」と「教師なし学習」、そして「強化学習」の3タイプがあり、それぞれに適した用途があります。それを示したのが、図3です。
図3:機械学習法の違いと用途

資料:総務省「AIネットワーク社会推進会議AI経済検討会 報告」などの公的資料をもとに編集部で作成
図3に示す通り、「教師あり学習」においてはラベル付きデータが必要となります。そのデータを作成するにはオリジナルデータに対して、ノイズを除去した上で、ラベル(正解データ)を付与するといった手間がかかります。
それに対して「教師なし学習」では、学習用データのノイズ除去は必要とされますが、学習用データに正解データを付与する必要はなく、その分の手間がかかりません。
また、教師なし学習で作り上げた学習済みモデルの場合、例えば、ネコを識別するためのモデルであれば、他の動物の画像が推論用データとして入力されたときに、それが何かは判断できません。ただし、他の動物の中からネコを識別することはできます。ゆえに、教師なし学習は、顧客のグループ化やWebサイト上での顧客行動にもとづくレコメンデーションなどの用途に適しているとされています。

一方、「強化学習」は、コンピュータに試行錯誤を行わせ、特定の行動に対して報酬を与えることで「何が良い行動か」を学ばせる学習法です。プロの囲碁棋士に勝利した Google の「AlphaGo」は、この学習法で鍛えられているとされています。
また、強化学習の分かりやすいユースケースとして、総務省では「二足歩行ロボットに歩く速度や脚の曲げ方について試行錯誤を行わせ、その過程で長い距離を歩いた場合に報酬を与えるといったプロセスを繰り返し、最終的には倒れずにスムーズな歩行ができるようにする」といった例をよく使用しています。
「機械学習」活用の現実解
機械学習の活用にはデータ分析のための専門的な知識が必要とされるほか、プログラミングに関するスキルも要求されます。
そのため、AIの技術やデータ分析に精通する人材や開発者がいない、または少ない企業にとっては、機械学習は活用のハードルがきわめて高い技術とされてきました。
ただし近年では、 Google やAmazon、Microsoft、IBMといった大手のクラウドプラットフォーマーが、AIを開発するためのフレームワーク(=機械学習の機能やアルゴリズムをセットにしたライブラリ)やAPI(=学習済みモデルを使うためのAPI)を、AIの開発・実行基盤とともに提供し、機械学習活用の敷居を下げ始めています(図4)。
図4:主要なクラウドプラットフォーマーの機械学習活用環境
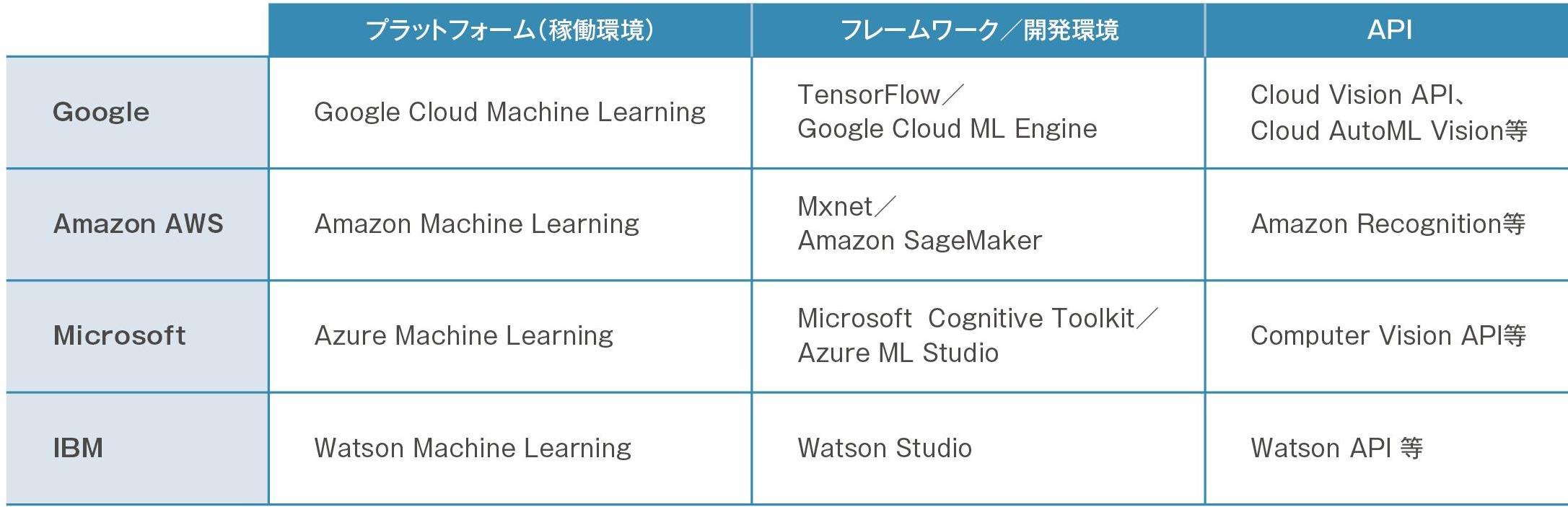
資料:総務省「AIネットワーク社会推進会議AI経済検討会 報告」などの公的資料をもとに編集部で作成
また、近年機械学習の一分野である生成AIが発展し、ChatGPTやGeminiを活用することで、専門知識を持たない人でも身近に機械学習を利用できるようになってきています。
今日では、マーケティング部門で使われるCRM(カスタマーリレーションシップマネジメント)やMA(マーケティングオートメーション)、BI(ビジネスインテリジェンス)などのアプリケーションにも機械学習や生成AIの機能が組み込まれているツールが増えています。
また、「Treasure AI」のように、機械学習フレームワーク(ライブラリ)が標準の機能として組み込まれているCDP(カスタマーデータプラットフォーム)製品もあります。こうした製品を使うことで、顧客をセグメント化して失注を予測したり、購入確度の高い見込み客を見つけたり、サイト来訪者の興味・関心に応じてレコメンドメッセージを表示したりするための予測モデルを容易に活用できるようになります。
先進事例に見るマーケティングでの機械学習活用の効果
上述したようなかたちでマーケティングにおける機械学習活用の環境が整備されるに従って、実践活用の裾野も広がりつつあります。
表2. 先進事例に見るマーケティングでの機械学習活用の効果
| トピック | 成果と課題 |
|---|---|
| 具体的な成果事例 | 有望見込み客の抽出によるCV向上、中古マンションの価格予測、予測モデル構築の自動化などが実現している。 |
| 成功への最重要ポイント | 最大の障壁は「データの不足」。学習に使える状態のデータをいかに収集・蓄積・管理できるかが、企業の競争力を左右する鍵となる。 |
例えば、Treasure AIを使う国内のある情報通信サービス企業では見込み客の行動履歴データを用い、機械学習でホットリード(有望な見込み客のリスト)をより正確に抽出する取り組みを展開、相応の成果をすでに手にしています。具体的には、機械学習を使って抽出したリードをターゲティングしてメールを配信した結果、コンバージョン(メールの開封率やクリック率)が従来比で数倍に伸びたケースもあるといいます。
また、CDPのユーザ企業で、不動産情報サイトを運営する会社では、中古マンションの価格予測モデルを機械学習で作り上げ、実サービスで活用しています。
さらに、アパレル事業やホテル事業を展開する、ある国内企業では、機械学習プラットフォームと顧客データを使いながら、商品ブランドごとの予測モデルの構築・検証・(予測結果の)可視化までを自動化するシステムの構築に成功しているといいます。

もっとも、マーケティングにおける機械学習の活用で成果を上げている企業は、分析対象のデータが十分に収集・蓄積できているところに限られています。総務省によれば、国内企業でのAI(機械学習)活用を阻む大きな障壁は、人材の不足だけではなく、学習に使えるデータが不足している点にあるといいます。
実際、同省の調査([1])によれば、2019年当時において機械学習のためのデータを十分に整備しているところは上場企業でも全体の1割程度でしかなく、多くがデータはあるものの使える状態になっていなかったり、そもそもデータの収集ができていない場合が見受けられます。
つまり、機械学習の活用に向けて最も重要なポイントは、学習に使えるデータがしっかりと収集・蓄積できているかどうかにあり、それはマーケティングでの機械学習の活用においても例外ではありません。
よくある質問(FAQ)
Q1: 機械学習とAI、ディープラーニングはどう違うのですか?
A1: AIは広義の「人工知能」を指し、機械学習はそのAIを実現する「手法の一つ」です。ディープラーニングは、ニューラルネットワークを用いた「機械学習の一種」であり、複雑なデータのパターンを自動抽出できる点が最大の特徴です。
Q2: 機械学習における「学習済みモデル」とは何ですか?
A2: 学習プロセスを通じて、コンピュータがデータからパターンを認識できるように確立されたモデルのことです。これを「推論プロセス」で活用し、新しいデータに対して識別や予測を行います。
Q3: マーケティングで機械学習を導入する際、最も重要なことは何ですか?
A3: データの収集・蓄積・整備です。どれほど高度なモデルを用いても、入力するデータが不足していたり、整理されていなかったりすると推論精度は上がりません。機械学習の活用戦略と、データを活用できる状態にする環境整備はセットで進める必要があります。

[1] 総務省・情報通信総合研究所(ICR)・日本経済研究センター(JCER)「AI・IoTの取組みに関する調査」


データ活用の最前線セミナー


