
データウェアハウス構築完全ガイド:基本設計からクラウド比較・移行戦略・成功事例まで -
データが部門ごとに分かれ、正しい数値がすぐに出せない、レポート作成に時間がかかるといった悩みを抱えていませんか。
多くの企業がこの課題に直面し、解決の鍵として注目しているのが「データウェアハウス(DWH)」です。DWHは、企業内のあらゆるデータを一元的に集約・整理し、経営判断や分析を支える中核的な仕組みです。
本記事では、DWHの定義と役割やデータレイク・データマートとの違い、導入時に押さえておくべきポイントを分かりやすく紹介します。自社に最適なDWHを選ぶための判断軸を理解し、データ活用を次のステージへ進めるための第一歩を踏み出しましょう。
データウェアハウス(DWH)構築のための基本知識

データ活用が企業活動全般の鍵を握る現在、データ基盤として欠かせないのが「データウェアハウス(DWH)」です。
ここでは、DWHの基本的な概念から、ほかのデータ基盤との違い、さらには導入時の選定ポイントまでを順を追って整理していきます。
データウェアハウス(DWH)とは?
まず、DWHとは何かを明確に理解することから始めましょう。
DWH の定義と役割
DWH(データウェアハウス)は、企業内のさまざまな業務システムから集めたデータを一元的に統合し、分析や意思決定に活用できる形で蓄積・提供する仕組みです。単なるデータ保管庫ではなく、経営戦略の裏側を支える「分析基盤」としての役割を担っています。
この仕組みにより、部門を超えたデータ統合や時系列分析、KPIのトラッキング、経営ダッシュボードの自動更新などが可能になります。つまりDWHは、企業が「過去を振り返る」だけでなく、「未来を予測し、意思決定を最適化する」ための中核的なインフラなのです。
DWH とデータレイク・データマートの違い
次に、よく混同されやすいデータレイクやデータマートとの違いを整理しておきましょう。
データ分析基盤を構築する際は、それぞれの役割と特性を理解したうえで、最適な組み合わせを選ぶことが重要です。
データレイクは、構造化・非構造化を問わず、あらゆるデータをそのまま保存できる仕組みで、柔軟性と拡張性が高い一方、データの整備や品質管理に手間がかかる傾向があります。
一方、DWHはあらかじめスキーマを定義した上で、分析しやすい構造化データを格納する点が特徴です。クエリ性能や分析効率に優れる反面、データ構造を変更する際は設計の見直しが必要になることもあります。
さらにデータマートは、DWHで蓄積したデータを基に、営業・人事・経理など特定の部門や目的に特化して抽出・整理した仕組みです。DWH全体の一部を用途別に最適化することで、ユーザ部門が自律的に分析を行いやすくなります。
宝石の加工に例えると、「データレイクは原石をためる場所」「DWHは原石を宝石に精製する場所」「データマートは磨かれた宝石を使う場所」と理解すると、それぞれの役割がより明確になるでしょう。
関連記事:データレイクとデータウェアハウスの違いを比較!使い分ける方法や導入のポイントも解説
関連記事:データマートの設計とは?データウェアハウスとの違い・設計をするための流れまで詳しく解説!
従来型 DWH の課題
これまで多くの企業ではオンプレミス型のDWHが中心でしたが、近年その限界が明確になっています。
特に、データ量の爆発的な増加やリアルタイム分析への需要拡大を背景に、従来型の仕組みでは次のような課題が浮き彫りになっています。
まず、オンプレミス環境ではハードウェアの性能やストレージ容量に制約があり、大量データや高頻度の更新に対応しづらい点が挙げられます。さらに、専用サーバや定期バッチ処理を前提とした運用は、人員負担や保守コストの増加を招きがちです。
また、定期的なバッチ処理に依存しているため、リアルタイムでのデータ反映や即時分析には不向きという構造的な制約もあります。
こうした背景から、クラウド化・サーバレス化・ストリーミングデータ対応などを含む「モダンDWH」への移行が加速しているのです。
データウェアハウスを選ぶ際のポイント
DWHの役割や構造的な違いを理解したところで、次に重要になるのが「どのようなDWHを選ぶか」という判断です。
企業のシステム環境や運用体制によって最適解は異なるため、ここでは導入形態・主要クラウドサービス・価格モデルの三つの観点から整理します。
オンプレ型 vs クラウド型
まず検討すべきは、DWHを自社で保有・運用する「オンプレミス型」にするか、クラウド事業者が提供する「クラウド型」にするかという選択です。
オンプレミス型の最大の利点は、既存のデータセンター資産を活用できる点にあります。レガシーシステムとの互換性が高く、データを完全に社内で管理できるため、厳しい情報統制が求められる環境にも適しています。
一方で、初期投資の大きさやスケーラビリティの制限、運用・保守にかかる人員負荷といった課題があります。
それに対してクラウド型は、インフラの構築やメンテナンスを事業者に委託できるため、導入スピードが速く、スモールスタートに適しています。処理能力やストレージ容量を柔軟に拡張でき、利用状況に応じてコストを最適化できる点も魅力です。
ただし、データ転送コストや通信遅延(レイテンシー)、既存システムからの移行作業、さらにはデータセンター所在地に関する法規制への対応など、クラウド特有のリスクにも注意が必要です。
最終的には、業務要件・セキュリティポリシー・運用リソース・予算といった複数の条件を総合的に評価し、自社に最も適した方式を選ぶことが求められます。
主なクラウドDWHサービスとその特徴
近年はクラウドDWH市場が急速に拡大し、各社が多様な特徴を持つサービスを展開しています。代表的な四つのサービスを比較してみましょう。
Amazonの Redshift は、AWSが提供するフルマネージド型のDWHで、カラムナーストレージによる高速クエリ処理と、AWSエコシステムとの高い親和性が特長です。既存のAWS利用企業にとっては、最も導入しやすい選択肢といえます。
Googleの BigQuery は、完全サーバレス型のDWHとして知られ、インフラ管理が不要な点が強みです。自動スケーリングによる高い拡張性と、ストリーミング処理を含むリアルタイム分析能力に優れ、大規模データ分析やデータサイエンス用途に適しています。
Snowflake は、マルチクラウド対応を実現した先進的なDWHで、ストレージとコンピュートを分離するアーキテクチャを採用しています。この設計により、複数ユーザが同時に処理を行ってもパフォーマンスが劣化しにくく、ゼロコピー共有などの独自機能も高く評価されています。
Azure Synapse Analytics は、Microsoft Azure上で動作する統合分析プラットフォームで、ETL処理やビッグデータ分析を含む幅広い機能を一体的に提供します。すでにMicrosoft 365やPower BIを利用している企業には特に親和性が高い選択肢です。
最後に、Databricksは、AIとデータ分析のための統合プラットフォームです。「レイクハウス」という概念を提唱し、データレイクのように非構造データも格納できる柔軟性とDWHとしてのデータ処理の仕組みを併せ持っている点が特長です。データエンジニアリングからBI、機械学習モデル開発までを単一基盤でサポートし、マルチクラウド環境での高度な分析に強みがあります。
これらのサービスには明確な強みと適用領域があるため、クラウド環境・データ量・分析要件・チーム体制などを踏まえて、最適な組み合わせを検討することが重要です。
価格モデル
どのサービスを選ぶにしても、コスト構造の理解は欠かせません。クラウドDWHでは、利用形態に応じて課金方式が異なるため、導入前にコストシミュレーションを行うことが重要です。
多くのサービスでは、データを保存する量に応じて料金が発生する「ストレージ課金」と、クエリ実行や処理に対して課金される「コンピュート課金」を組み合わせています。
例えばBigQueryは、実行したクエリのスキャンデータ量に基づく従量課金制を採用しており、使った分だけ支払う明確なモデルです。
一方、利用量が安定している企業では、月額固定料金の「定額制」を選ぶことで、コストを予測しやすくなります。
このほかにも、運用・監視・データ転送などの周辺コストも見落とせません。特に、運用担当者の人数やスキルコストまで含めて総保有コスト(TCO)を試算することで、初期費用の安さだけでは見えない「真のコスト差」を可視化できます。
最終的には、データ量・クエリ頻度・スケーラビリティ要件・既存クラウドとの統合性といった観点を踏まえ、複数のサービスを比較・シミュレーションし、最も費用対効果の高い選択を行うことが理想です。
データウェアハウス構築の全体ロードマップと実践ステップ
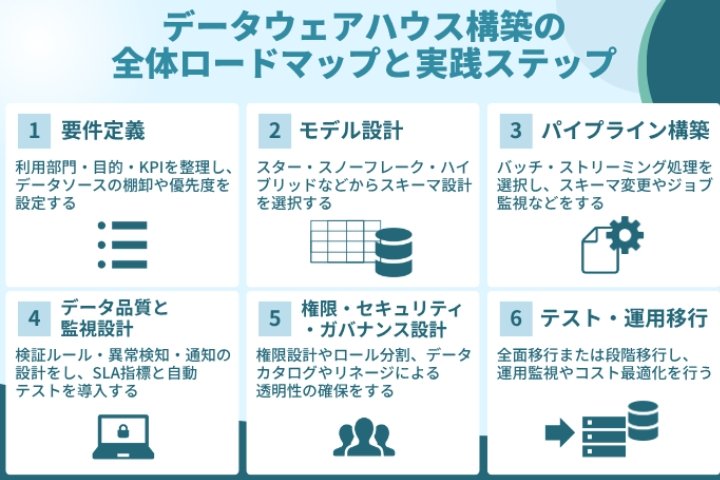
ここまでで、DWHの選定ポイントを整理しました。次に、実際の構築をどのようなステップで進めていくのかを見ていきます。
DWHプロジェクトは単なる技術導入ではなく、全社的なデータ活用文化を築くための変革プロセスでもあります。ここでは、企画段階から運用定着までの流れを六つのフェーズに分けて解説します。
1. 要件定義:DWHの目的とスコープを明確化する
最初のステップは、プロジェクト全体の方向性を決める「要件定義」です。
この段階で利用部門、分析目的、主要KPIを整理し、どのデータをどの優先順位で扱うかを明確にしていきます。目的やスコープを曖昧にしたまま進めると、後の工程で仕様変更が頻発し、コストや期間が膨らむ原因になります。
まず、営業・マーケティング・製造・管理部門といった利用部門ごとに、データを活用してどのような意思決定を支援したいのかを洗い出します。例えば「顧客LTVの可視化」「在庫最適化」「コスト削減」など、具体的な業務課題を出発点にするとよいでしょう。
そのうえで、売り上げやCAC(顧客獲得コスト)、在庫回転率といったKPIを明確化し、基幹システムやCRM、広告ログ、IoTセンサーなどのデータソースを棚卸して優先度を設定します。
最終的には、「どの範囲をいつまでに構築するか」を定義し、全関係者が同じ目標を共有することがこのフェーズの成果です。
2. モデル設計:データ構造と分析粒度を定義する
要件が固まったら、次はデータモデルの設計に進みます。
これは、どのような構造でデータを格納・関連づけるかを設計する工程であり、DWHの“設計図”にあたる部分です。
代表的な設計手法には、単純で高速なクエリに向く「スター・スキーマ」、階層構造を持つ「スノーフレーク・スキーマ」、それぞれを組み合わせた「ハイブリッド設計」などがあります。
正規化と非正規化のバランスをどう取るかも重要で、分析パフォーマンスを重視する場合は、非正規化寄りの設計が採用されることが多いです。
また、分析の粒度をあらかじめ定義しておくことも重要です。例えば日次、月次、あるいはイベント単位など、どの単位でデータを扱うかを明確にしておくことで、後から発生しがちなデータ統合の不整合や、レポート精度のばらつきを防ぐことができます。
この段階で堅牢なモデルを設計しておくことが、将来的な拡張や分析要件の多様化にも柔軟に対応できる鍵となります。
3. パイプライン構築:ETL/ELT処理を設計・実装する
データモデルを定義したあとは、次のステップとしてデータを実際に流し込む仕組みを構築します。ここで重要になるのが、データを収集・変換・格納するための一連の流れであるパイプラインの設計です。
ETL(Extract, Transform, Load)またはELT(Extract, Load, Transform)のプロセス設計は、DWHの生命線です。
リアルタイム分析を重視するならストリーミング処理、定期バッチ更新が中心ならバッチ処理を選択します。どちらの方式でも、スキーマ変更やデータ構造の変化に柔軟に対応できる設計が求められます。
さらに、ジョブの監視やエラー発生時の自動リトライ、負荷分散などの仕組みを整えることで、安定的なデータ供給が可能になります。
ロード時間の短縮や圧縮率の最適化、パーティショニング設計といったパフォーマンスチューニングもこの段階で行われます。こうして、DWH全体を支える堅牢なデータ基盤が完成します。
関連記事:ETLとは? - 概念・関連用語とツール活用のメリット・比較のポイントを解説
4. データ品質と監視設計:信頼性と安定性を担保する
どれほど優れたシステムでも、データの品質が確保されていなければ正しい意思決定はできません。このフェーズでは、データ品質の検証ルールを定義し、異常検知や通知の仕組みを整備します。
具体的には、NULL値や重複データ、異常値などを自動でチェックするルールを設定し、異常発生時には即座にアラートを送る監視体制を構築します。
また、ETL完了時間や遅延件数などのSLA(Service Level Agreement)を指標化することで、品質基準を数値で管理できるようになります。
さらに、ジョブ実行ログやレコード件数の自動テストを導入すれば、システム変更やスキーマ追加時の不具合も早期に発見できます。
品質監視の自動化は、DWHの「信頼性を継続的に保証する」ための要です。
5. 権限・セキュリティ・ガバナンス設計:透明性と統制を実現する
データウェアハウスには複数の部門がアクセスするため、誰がどのデータを利用できるのかを明確に定義し、適切に管理する仕組みが不可欠です。特に金融機関や公共機関などでは、データの透明性と説明責任を確保するために、厳格なガバナンス設計が求められます。
まず、データ基盤構築に際しては、単に権限を細分化するだけではなく、ビジネス方針に基づくガバナンス設計が不可欠です。サービス要件・業務要件を明確にしたうえで、以下の観点を整理し、“自社が実現したいデータ活用像”に沿ってルールを定義します。
- 理想のビジネス像策定(グランドデザイン):どの顧客価値・意思決定をデータで支えるかを明確化
- サービス/業務要件の策定:事業戦略と整合したデータ活用範囲・粒度の設定
- アクセス制御・権限管理:ロールごとに閲覧・更新範囲を設定し、不要なアクセスを防止
- データ分類と保護レベル定義:機密/社外秘/公開データ分類と保護方法(暗号化・マスキング)
- 個人情報・プライバシーポリシー策定:個人データの取得・利用・保存・廃棄ルールを明確化
- 監査ログ/監視基盤の整備:アクセス・変更履歴の追跡、異常検知の自動化
- データライフサイクルの設計:生成〜加工〜保管〜アーカイブ〜廃棄のルール化
- データ品質管理:品質基準、チェックルール、エラー時の対応フロー
- 従業員教育・意識醸成:ガバナンスを“現場が守れる仕組み”として運用定着
インキュデータでは、上記の要件整理〜ルール設計〜運用導入〜教育まで一気通貫で支援しています。
さらに、データカタログやリネージ(データ来歴)を整備することで、「誰が・いつ・どのデータを取得・加工したのか」を可視化できます。こうした仕組みは、メタデータ管理ツールを導入することで効率的に運用することが可能です。
また、暗号化やアクセスログ、匿名化・マスキングなどのセキュリティ設計を組み合わせることで、透明性と安全性の両立を実現できます。
当社では、メタデータ管理ツール OpenMetadata の導入支援を行っており、次のような仕組みを実現できます。
- 定期的なデータ品質チェックを自動で実行し、異常を早期に検知できる。
- データの所在や業務上の意味をカタログ上で一元管理し、検索性と理解度を向上させる。
- データ処理の流れ(リネージ)を自動的に取得し、データの来歴を追跡できる。
このような統合的なガバナンス設計によって、DWH全体の信頼性が高まり、経営層から現場担当者までが安心してデータを活用できる環境を構築できます。
6. テスト・運用移行:段階的導入で安定稼働へ
構築が完了したら、システムの切り替えと運用定着の段階に移ります。
このフェーズでは、全面移行か段階移行かを判断し、リスクとコストのバランスを取ることが重要です。
全面移行は短期間での刷新が可能ですが、トラブル発生時の影響が大きくなります。
一方、段階移行は部門単位で順次切り替える方法で、初期リスクを抑えながら安定運用を図れます。
移行後は、実際のクエリ負荷やデータ量、利用状況をモニタリングし、リソース配分やコスト最適化を継続的に行うことが求められます。
これにより、DWHを単なるシステムではなく「組織の知的資産」として定着させることができます。
データウェアハウス構築の成功事例

ここまでの設計・運用の要点を踏まえ、実務でどのような価値が生まれるのかを具体例で確認します。業界ごとにデータの性質や制約は異なりますが、適切なモデル設計とガバナンス、そして段階的な運用定着という共通原則が成果を左右します。
製造/IoTデータ統合事例
製造現場ではセンサーや稼働ログから高頻度の時系列データが継続的に発生します。これらをDWHへ統合し、設備ごとの特性を踏まえた時系列モデルを設計することで、不良兆候の早期検知や稼働率の最適化につながります。
ストリーミングとバッチを用途別に使い分け、メタデータでセンサーの配置や校正履歴を管理することで、原因分析の再現性が高まります。初期段階で閾値設定や異常スコアの検証計画を用意し、現場の知見を反映しながらモデルを更新していく運用に移行すると、予知保全の精度が安定します。
マーケティング統合/LTV可視化事例(株式会社TOAI)
西日本を中心にカラオケチェーンを展開するTOAIは、店舗アプリとオンラインサービスの両面で顧客接点を拡張し、データに基づく意思決定を加速させました。
会員情報、予約・決済、アプリ行動、広告流入など、部門ごとに分断されていたデータをDWHで統合し、顧客単位で行動を追跡できるように設計した結果、予約導線の改善や単価向上を支える検証サイクルが機能しています。Snowflakeを中心とした基盤によって分析の同時実行性を確保し、MA(マーケティングオートメーション)によるセグメント配信でコミュニケーションの粒度を高めました。
プロジェクトはUI/UX改善とログ分析からスタートし、可視化と施策検証を繰り返す運用へと発展。さらに、社内のスキルトランスファーを並行して進めたことで、現場主体の仮説検証が定着し、LTV向上と予約コンバージョンの改善を継続的に実現しています。
規制業界におけるガバナンス事例(金融・保険)
金融や保険の分野では、データの取り扱いに厳格な統制が求められます。アクセス権限と監査証跡を基盤レベルで一貫させ、個人情報については匿名化やマスキングを処理系に組み込み、用途別の再識別リスクを事前評価することで、業務の俊敏性と法令遵守を両立できます
データカタログとリネージを運用に密着させ、レポートやモデルの出力がどのソースに依拠しているかを常時たどれる状態を保つと、説明責任を果たしやすくなります。モデル更新やスキーマ変更を変更管理プロセスに組み込み、SLAに連動した品質検査を自動化することで、障害時の影響範囲が明確になり、復旧までの時間が短縮します。
まとめ

本記事では、「何のために」「どのように構築するか」「どのサービスを選ぶか」「移行時に注意すべき点」「成功事例に学ぶポイント」までを体系的に整理しました。
データウェアハウス構築は単なるシステム導入ではなく、業務要件の明確化・データモデリング・運用設計・ガバナンス設計を一体で考える総合プロジェクトです。これらが噛み合うことで初めて、データが経営判断や事業成長を支える「資産」として機能します。
まずは、自社の業務課題とKPIを整理し、適切なデータモデルとパイプライン設計を行いましょう。また、クラウドDWHの特性や価格モデルを理解し、自社に合った構成を検討することが重要です。
さらに、運用フェーズではモニタリングや品質管理、権限設計を継続的に改善し、組織全体でデータ活用の文化を育てていくことが、長期的な成功につながります。
検討項目が多岐に渡るDWHプロジェクトには「信頼できるパートナー」の存在が欠かせません。
インキュデータでは、戦略策定から構築・運用・社内定着までをワンストップで支援し、SnowflakeやDatabricksを中心としたモダンDWH環境の構築・データ統合・人材育成までを包括的にサポートしています。
データ活用を次のフェーズへ進めたい企業は、ぜひインキュデータにご相談ください。組織の現状に寄り添いながら、“使えるデータ基盤”をともに構築するパートナーとして伴走します。


データ活用の最前線セミナー


