
データ統合とは?目的・方法・注目トレンドまで徹底解説 -
部門ごとに散らばったデータがつながらず、定義の違いや更新のズレに毎回悩まされていませんか。レポートの整合性が取れず議論が空回りし、セキュリティや権限管理も人任せになりがちだと感じるはずです。
本記事では、こうしたモヤモヤを解きほぐす鍵として「データ統合」の意味を明確にし、サイロ解消や意思決定の高速化、ガバナンス強化につながる目的を、実務目線で整理します。
データ統合とは

まず最初に、データ統合という言葉の意味を整理しておきましょう。
データ統合とは、企業内外の異なるシステムやフォーマットに分散している情報を統一・集約し、整ったひとつのデータセットとして活用できるようにするプロセスを指します。
例えば、あるシステムでは日時が「2023/01/01 00:00」と登録され、別のシステムでは「202301010000」と登録されている場合、このままでは同じデータであっても一致せず、分析やレポーティングの際に不整合が生じてしまいます。データ統合は、こうした表記や構造の違いを吸収し、整合性を保った状態でデータを扱える状態を作り出します。
この概念には「相互運用性(interoperability)」という考え方も深く関わっています。相互運用性とは、単にデータを一箇所に集めるだけではなく、異なるシステム同士が相互にデータをやり取りし、必要なときに必要な情報を活用できるようにする能力を意味します。
つまり、データ統合とは単なるデータの集約ではなく、全社的にデータを活用できる環境を整えるための基盤づくりそのものなのです。
データ統合を実施する目的
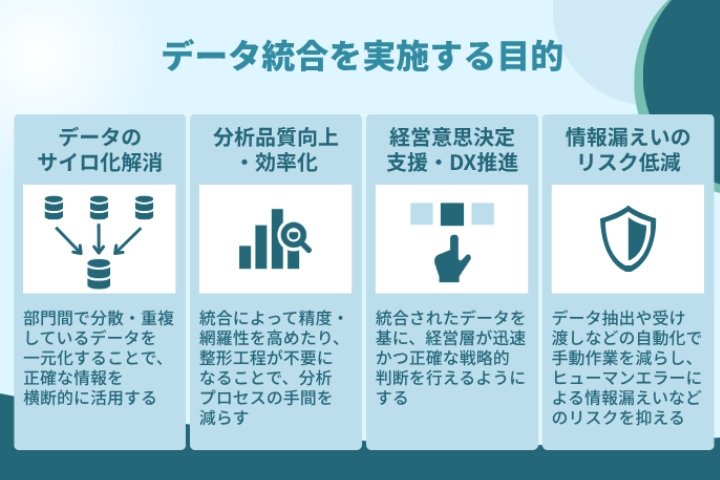
では、なぜ多くの企業がいまデータ統合に注目しているのでしょうか。その背景には、単なる業務効率の改善だけでなく、様々な目的があります。
ここでは、代表的な四つの目的を整理して見ていきましょう。
部門間でのデータのサイロ化を解消する
企業では、営業・マーケティング・生産・人事などの部門ごとに異なるシステムやデータ形式が使われていることが多く、それぞれの部門が独立してデータを管理している状況がよく見られます。
この状態を放置すると、同じ指標に対して複数の部門が異なる定義で分析を行い、結果的に重複作業や整合性の取れない報告が発生してしまいます。
データ統合を進めることで、部門間の壁を取り払い、共通のデータ基盤をもとに議論や分析を行える体制を整えることが可能になります。いわゆる“データのサイロ化”を解消し、全社的なデータ活用を促進する第一歩となります。
関連記事:データのサイロ化とは?解消するメリット・サイロ化が生じる理由・問題点・解決方法を中心に詳しく解説!
分析の品質を高め、業務を効率化する
データが統合されていない環境では、分析担当者が「どのデータが最新なのか」「どの形式を使えば結合できるのか」といった確認作業に多くの時間を費やしてしまいます。その結果、本来集中すべきデータ分析や示唆の抽出が後回しになるケースも少なくありません。
データ統合を行えば、データの重複や欠損を事前に整理でき、分析時の前処理作業を大幅に削減できます。その成果として、より精度の高い分析を短時間で行えるようになり、意思決定までのスピードも向上します。
経営意思決定を支援し、DXを推進する
統合されたデータは、経営層が的確でタイムリーな判断を下すための強力な土台になります。例えば、顧客情報・販売データ・生産データを横断的に分析できれば、需要予測や在庫管理の最適化はもちろん、新しいビジネス機会の発見にもつながります。
また、デジタル変革(DX)を推進する上でも、正確かつ一貫したデータ基盤は欠かせません。データ統合は、単なるIT部門の作業ではなく、企業全体の変革を支える戦略的な取り組みとして位置づけられています。
情報漏えいのリスクを低減し、ガバナンスを強化する
データが各部門に散在していると、どこにどの情報が保存されているのかを正確に把握しづらくなり、セキュリティリスクが高まります。アクセス権限の不統一や、担当者ごとの管理に依存する状態が続けば、情報漏えいや誤用のリスクも避けられません。
データ統合によって、管理ルールを明確にして、データの所在や、アクセス権限を整備することで、リスクを体系的に管理できます。ガバナンスやセキュリティ体制の整備が進み、組織としてより安全にデータを活用できる環境が整います。
このように、データ統合には、単なる業務効率化にとどまらず、企業文化や意思決定のあり方を根本から変える力があります。次に、こうした目的を実現するためにどのような統合の方式があるのかを見ていきましょう。
データ統合時の課題と対応ポイント

データ統合は、単にシステムをつなぐ作業ではなく、企業全体のデータを「正しく・安全に・継続的に」活用できるようにするための基盤整備です。
しかし、実際の現場では理想通りに進まないケースも多く、いくつかの典型的な課題を乗り越える必要があります。ここでは、それぞれの課題と有効な対応の方向性を見ていきましょう。
データクレンジングにかかる工数の多さ
異なるシステムやフォーマットで蓄積されたデータを統合する際には、欠損値・重複データ・形式の不一致といった問題が避けられません。これらを放置すると、統合後のデータの信頼性が損なわれ、分析精度や意思決定に誤りをもたらす可能性があります。
この課題に対処するには、まずデータ統合前にデータプロファイリングを行い、どの項目に欠損や重複があるか、どのシステム間で定義がずれているかを把握することが重要です。そのうえで、ETLツールやデータクレンジング機能を活用して整合性を確保すれば、統合後の品質を大幅に向上できます。
*データプロファイリング:データの品質管理面での特徴を明らかにすること
レガシーシステムとの接続の難しさ
長年運用されてきたオンプレミスのシステムや古いデータベースは、APIが存在しなかったり、独自仕様でフォーマットが特殊だったりする場合があります。こうしたシステムとの連携は、新しい環境との互換性を取る上で大きな障壁になります。
この問題を解消するには、一度に全てを接続しようとするのではなく、段階的に統合を進めていくことが効果的です。必要に応じて、既存システムをラッピングしたり、専用のコネクタを開発したりして、徐々に互換性を高めていく方法が現実的です。
関連記事:データ連携とは? - 目的から課題・基盤を構築する方法まで徹底解説
運用コストとスケーラビリティの確保
データ統合は一度実施すれば終わりではなく、データ量が日々増加し、システム構成が変化する中で運用を継続していく必要があります。データパイプラインの保守や監視、追加データへの対応には時間もコストもかかります。
そのため、運用設計段階から自動化とモニタリングを前提に仕組みを構築することが欠かせません。さらに、クラウド環境を活用することで、データ量の増加にも柔軟に対応でき、スケーラビリティを確保しながらコスト効率のよい運用が可能になります。
データ統合を担える人材の不足
データ統合には、データ設計、変換ルール作成、システム連携など、専門的な知識と経験が求められます。特に、BIやデータエンジニアリングの体制が整っていない企業では、適切に統合を進められる人材が限られている場合があります。
この課題に対しては、社内でのスキル育成を進めると同時に、外部パートナーや専門ベンダの支援を受けることが現実的です。
また、ノーコード/ローコード型のデータ統合ツールを導入することで、非エンジニアでも一定の統合・運用を担えるようになり、人材不足を補うことができます。
プライバシーとセキュリティへの対応
統合されたデータは複数部門で横断的に利用されるため、個人情報保護やアクセス制御、内部統制などの観点で新たなリスクが生じます。もし統合後のデータ管理ルールが曖昧なままだと、情報漏えいや誤用のリスクが高まります。
このため、統合の設計段階からデータガバナンスの方針を定め、アクセス権限の設定、ログ取得、データマスクや削除ポリシーを明確にすることが重要です。データを活用するほどにセキュリティの重要性は増すため、技術的対策と運用ルールの両面で管理体制を整えることが求められます。
データ統合のプロジェクトは、技術面だけでなく運用や人材、ガバナンスといった多面的な課題への対応が欠かせません。
データ統合の方式とアーキテクチャ

ここからは、実際にデータ統合を実現するための具体的な方式やアーキテクチャについて見ていきましょう。
企業によって最適な仕組みは異なりますが、代表的な3つのアプローチを理解しておくことで、自社の状況に合った構成を検討しやすくなります。
ETL/ELT
最も広く知られているのが、ETL(Extract-Transform-Load)とELT(Extract-Load-Transform)の二つのパターンです。
ETLは「抽出 → 変換 → ロード」という順序でデータを処理し、分析に適した形式へと整形したうえでDWH(データウェアハウス)に格納する方法です。長年にわたり採用されてきた伝統的な方式で、オンプレミス環境でも安定した運用が可能です。
一方、ELTは「抽出 → ロード → 変換」の順に処理を行います。クラウドDWHなどの高い計算能力を活用し、データをまず格納してから変換を行う点が特徴です。大量データやスケーラビリティを重視するケースでは、ELTのほうが効率的な場合もあります。
どちらを選択するかは、データ量やリアルタイム性、既存インフラとの親和性、処理コストなどを総合的に考慮して判断する必要があります。
関連記事:ETLとは? - 概念・関連用語とツール活用のメリット・比較のポイントを解説
仮想統合・リアルタイム統合(データ仮想化・ストリーム処理)
近年は、物理的にデータを移動・変換・格納する方式だけでなく、データ仮想化(Data Virtualization)を活用した“仮想的統合”のアプローチも注目されています。これは、異なるデータソースを一か所に移動させることなく、統合ビューとして扱う技術です。
例えば、営業データと顧客データをリアルタイムに照合することで、あたかも一つのデータベースのように活用できます。
さらに、ストリーム処理やリアルタイムETL、CDC(Change Data Capture)といった技術を組み合わせることで、イベント発生時に即座にデータを取り込み・更新する「リアルタイム統合」も実現可能になっています。高速な意思決定や即時分析を求める企業にとって、これらの技術は欠かせない選択肢となりつつあります。
統合基盤の構成パターン
最後に、データ統合を支える基盤アーキテクチャの代表的な構成を整理しておきましょう。企業の目的やデータ特性によって最適解は異なりますが、主に三つのパターンが存在します。
1つ目はデータウェアハウス中心型です。主に構造化データを一元的に蓄積し、分析・レポーティング用途に特化した設計です。データ品質を重視する企業や、定型的なBI分析を中心とする組織で多く採用されています。
2つ目はデータレイク中心型で、構造化・非構造化を問わず膨大なデータをそのまま蓄積し、AI分析や機械学習などの多様な活用を前提にしています。柔軟性は高いものの、運用やガバナンス設計が鍵となります。
そして3つ目がハイブリッド型です。DWHとデータレイクを組み合わせ、リアルタイム処理・バッチ処理・高度分析を適材適所で実行できる構成です。近年ではこのハイブリッド型を採用する企業が増えており、データの性質や活用目的に応じて最適な場所で処理を行う考え方が主流になっています。
このように、データ統合の方式とアーキテクチャは一様ではありません。自社のデータ特性、業務要件、将来的な拡張性を踏まえて最適な構成を設計することが、持続的なデータ活用基盤の構築につながります。
データ統合の進め方・ステップ

ここからは、実際にデータ統合プロジェクトをどのように進めていくか、その基本的な流れを整理していきます。
闇雲にツールを導入するのではなく「なぜ統合するのか」「どの範囲を対象とするのか」を明確にすることが、成功の第一歩です。プロジェクトの初期段階から目的と優先順位を明確にしておくことで、仕様のブレや基盤構築後の運用トラブルを防ぐことができます。
現状調査と目的定義
最初のステップは、データを活用して何を実現したいのかを明確にした上で、現状のシステム構成とデータソースを正確に把握することです。どの部門・システムのデータを対象にし、どのような目的で統合を行うのかを定義します。
データ活用の目的の明確化については、例えば「販売実績と顧客情報を連携してLTVを分析したい」「リアルタイムで在庫状況を把握したい」など、具体的な利用シーンを設定することが重要です。
目的と対象範囲が曖昧なまま進めると、統合作業が複雑化し、最終的な成果が見えづらくなります。初期段階で関係部門と合意形成を行い、ゴールイメージを共有しておきましょう。
データ設計・マッピング
目的と対象が定まったら、次に行うのはデータ設計とマッピングです。ここでは、どのデータ項目(スキーマ)を統合対象にするのかを決め、項目間の対応関係を設計します。
具体的には、システムごとに異なる属性名やフォーマットを統一する必要があります。例えば「日付形式の統一」「IDの重複排除」「欠損値の補完」などのルールを定義します。
この工程は、後工程の自動化やデータ品質を左右する中核部分です。変換ルールの設計に時間をかけ、メタデータ管理を適切に行うことが、安定した統合基盤を築く鍵となります。
関連記事:顧客ID統合とは?重要性とメリット・実践方法について詳しく解説!
実装・検証
設計が固まったら、いきなり本格運用に移るのではなく、まずは小規模なPoC(概念実証)を実施します。PoCでは、実際のデータを使って統合プロセスを試し、性能や品質、運用負荷を検証します。
課題が見つかれば早期に修正し、本番環境への展開に備えます。本格導入後は、継続的な監視と変更管理が欠かせません。新たなデータソースの追加や仕様変更にも柔軟に対応できる体制を整えておくことで、長期的に安定した運用が実現します。
データ統合の実施事例

TOAI:カラオケ体験価値を10倍にするデータ活用基盤の構築
カラオケチェーン「ジャンカラ」を展開する株式会社TOAIは、「カラオケ体験価値を10倍にする」というビジョンのもと、データドリブン経営へと舵を切りました。
インキュデータの支援を受け、ジャンカラ公式アプリのUI/UX改善を皮切りに、Snowflakeによるデータ基盤構築やMA(マーケティングオートメーション)を活用したCRM導入を進めました。これにより、予約データや行動データを横断的に分析し、顧客属性に応じたパーソナライズ施策を展開。結果として予約コンバージョン率や収益率が向上し、アプリ経由の予約が全体の6割を超える成果を上げています。
さらにオンラインアプリ「UTAO」との連携を通じて、リアルとデジタルが融合する新たな顧客体験を創出し、業界全体の価値向上を見据えたデータ活用を進めています。
CASIO:顧客データ統合を核にしたユーザ価値中心への転換
カシオ計算機は、グローバルに点在する接点で生まれるデータを共通IDで束ね、ユーザ単位で活用できる基盤を整備しました。
直販サイトやアプリ、店舗、サポートにまたがる行動・購買・利用履歴を統合し、UCPとUDPを連携させてコミュニケーションとデータ活用を一体設計にしています。嗜好性・ホット度・ロイヤリティの三軸でユーザ理解を深め、適時に最適な内容を届ける運用へ移行しました。
さらに、この統合基盤を各地域へ展開し、開発・生産・営業・CSまでをデータでつなぐ「ユーザ中心のバリューチェーン」の実装を進めています。
サンスター:CDPで接点データを統合し、ロイヤル育成と体験向上を加速
サンスターは、自社EC、自社コミュニティ「Club Sunstar」、おくち元気チェックなどの接点で生まれる行動・購買・ヘルス関連データをCDPに統合し、ユーザ単位での理解を深めています。
部門横断で目的を定義し、データ分析とユーザインタビューを組み合わせて、関心の高まりや悩みに即したコンテンツと提案を最適化しました。その結果、メールや広告の成果が改善し、ECでは継続購入につながる導線が強化されました。
得られた洞察を製品改良や新サービス設計にも還元し、セルフケアとプロケアをつなぐ体験づくりへ展開しています。
今後の動向・注目トレンド

データ統合の世界は、ここ数年で大きな転換期を迎えています。クラウド活用の拡大やリアルタイム分析の一般化に伴い、従来のETL中心の仕組みから、より柔軟で自律的な統合モデルへと進化が進んでいます。
ここでは、今後のデータ統合を形づくる四つの注目トレンドを紹介します。
iPaaS/ハイブリッド統合
クラウドサービス(SaaS)の利用が拡大する一方で、基幹システムは依然としてオンプレミスに残る企業も多く存在します。こうした環境の橋渡し役として注目されているのが、iPaaS(Integration Platform as a Service)です。
iPaaSは、クラウドとオンプレの間をシームレスにつなぎ、API連携やデータフローを一元的に管理します。複数のSaaSを併用するケースでも、リアルタイム性を損なわずにデータを統合できる点が大きな魅力です。
AI/機械学習を使った変換支援
データ統合におけるAI活用も急速に進んでいます。特に、マッピング作業や変換ルールの作成、データクレンジング、異常検知といった手間のかかる工程をAIが支援する動きが広がっています。
これにより、人的作業の削減だけでなく、品質のばらつきを抑えた精度の高い統合が可能になります。学習型モデルが導入されることで、統合プロセスそのものが自動的に改善されていくという将来像も描かれています。
Zero-ETL(ノーコード統合)
次に注目されているのが「Zero-ETL」や「ノーコード統合」と呼ばれるアプローチです。
これは従来のようにETLツールでデータを抽出・変換・ロードする手間をなくし、システム間でデータを直接連携・活用できる仕組みを指します。
特にAWSやGoogle Cloudなど主要クラウドベンダーが提供するサービスでは、分析基盤やBIツールがバックエンドで自動連携する構想が進んでおり、将来的に主流化する可能性があります。
ただし、ガバナンスや品質管理の仕組みをどのように確保するかが課題として残ります。
Data Fabric/Data Mesh 概念
最後に、データ統合の思想そのものを変える概念として「Data Fabric」や「Data Mesh」が挙げられます。
これらは、従来の中央集約型アーキテクチャに代わり、分散されたデータをメタデータでつなぐ「分散型統合」の考え方です。各部門やチームが自律的にデータを管理しつつ、組織全体で統一されたガバナンスのもとでデータを活用できる点が特徴です。クラウドとAIの発展により、こうした柔軟なデータ活用モデルが現実味を帯びてきています。
このトレンドは、単なる技術革新ではなく、データを「企業資産」としてどう扱うかという経営戦略の変化を示しているといえるでしょう。
今後は、統合そのものを目的とするのではなく、統合によってどのようにビジネス価値を生み出すかが問われていく時代に移行していくでしょう。
まとめ

データ統合は、単に情報を集めるための仕組みではありません。全社のデータを正しく結びつけ、事業部門が迅速かつ的確な意思決定ができる環境を整えることで、組織の競争力を高める戦略的な取り組みです。
目的と方式を明確にし、計画的にステップを踏んで課題へ対処することで、統合は単なるシステム構築から「価値創出の基盤」へと進化します。
iPaaSやAIによる自動変換、Zero-ETL、Data Fabric / Data Meshといった新しい潮流が示すように、データ統合の形は今まさに転換期を迎えています。クラウドやAIを柔軟に取り入れ、分散環境でも統一的なデータ活用を実現できる設計こそが、今後の企業成長を左右します。
インキュデータでは、データ戦略立案からデータ活用基盤の構築、運用・人材育成までをワンストップで支援しています。データ統合を「ビジネス価値の源泉」に変えたい企業は、ぜひ一度ご相談ください。


データ活用の最前線セミナー


