
データ連携とは?iPaaS・ETL・EAIの違いと企業が選ぶべき最適な手法 -
SaaSの普及で様々な機能の導入が容易になり、また速くなった一方、データが部門やシステムごとに分断され、「欲しい数字がすぐ出ない」「結局CSVで集計している」といった悩みが増えています。
データ連携は、このデータの分断を解消して現場の手作業を減らし、企業の意思判断にリアルタイムのデータを活用するための土台になります。
本記事では、データ連携の定義から、ETL・EAI・iPaaSの違いと使い分け、選定で失敗しない判断軸、導入の進め方までを整理し、自社に合う最適な手法を具体的に描けるように解説します。
データ連携とは何か

企業活動においてデータの重要性が高まる中で、「データ連携」という言葉を耳にする機会は増えています。しかし、その意味や必要性を体系的に理解できていないまま使われているケースも少なくありません。
まずは、データ連携がどのような概念であり、なぜ企業にとって欠かせない存在になっているのかを整理していきます。
データ連携の定義と企業における必要性
データ連携とは、異なるシステムやアプリケーションの間でデータをやり取りし、必要な情報を必要なタイミングで利用できる状態を維持する仕組みを指します。企業内には、基幹システム、業務部門ごとに導入されたSaaS、独自に管理されているデータベース、各種クラウドサービスなど、性質の異なるデータソースが数多く存在しています。
これらが個別に稼働している状態では、情報は部門単位で分断され、全社的な状況把握や横断的な分析が難しくなります。その結果、同じデータを何度も加工・集計する非効率が生じたり、意思決定に時間がかかりやすくなります。
データ連携は、このような意思決定の分断を解消し、業務効率の向上やデータ活用の高度化を支える基盤として、現代の企業に不可欠な役割を果たしています。
データ連携は業務や分析の土台となる重要な仕組みですが、なぜ今多くの企業がその必要性を強く意識するようになったのでしょうか。次に、その背景を整理します。
企業がデータ連携を求める背景
近年、DXの推進や経営判断のスピード向上が強く求められるようになり、データ連携の重要性は一段と高まっています。
特にSaaSの普及によって、部門ごとに最適なツールを柔軟に導入できる環境が整った一方で、データが各システム内に閉じたまま蓄積され、サイロ化しやすくなりました。その結果、必要な情報を集めるために手作業での集計やファイル共有が発生し、現場の負担が増えるケースも少なくありません。
さらに、経営層からは売り上げや在庫、顧客動向といった指標を「今の数字」として把握したいという要求が高まっています。従来のような定期バッチ処理や属人的な集計作業では、変化の激しい市場環境に対応しきれず、意思決定の遅れにつながるリスクが顕在化しています。
このような状況を背景に、リアルタイム性と全社的なデータ一貫性を両立させる手段として、データ連携があらためて注目されています。
企業が抱える典型的なデータ連携の課題
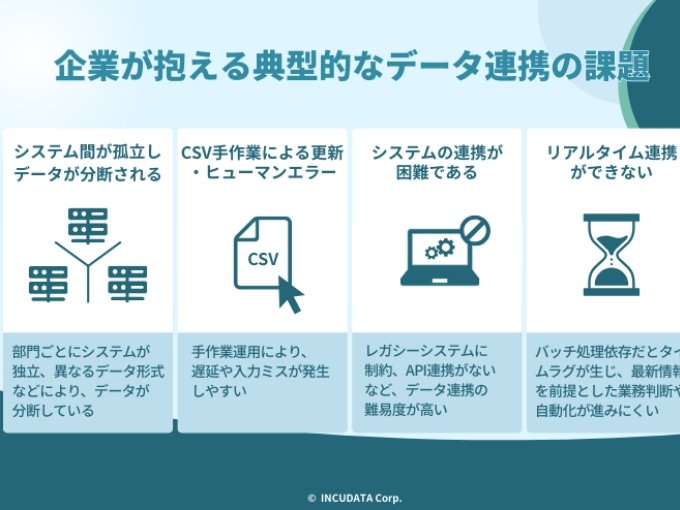
データ連携の重要性が広く認識される一方で、実際の企業現場では多くの課題に直面しています。これらの課題は特定の業種に限られたものではなく、多くの企業に共通して見られる点に特徴があります。
ここでは、特に発生頻度の高い代表的な課題について説明します。
システム間が孤立しデータが分断される
部門ごとに業務最適化を進めた結果、異なるシステムが独立して導入されている企業は少なくありません。このような環境では、システムごとにデータ形式や管理ルールが異なり、部門を横断したデータ活用が難しくなります。
その結果、同一の顧客情報や取引データが複数のシステムで個別に管理される状態が生まれ、情報の不整合や更新漏れが発生しやすくなります。データの信頼性が低下すると、分析結果やレポートの精度にも影響を及ぼし、意思決定の質を下げる要因になります。
このような構造的な分断に加えて、運用面での課題が重なることで、さらに問題が複雑化するケースも多く見られます。
CSV手作業による更新とヒューマンエラー
システム間の正式な連携手段が整備されていない場合、CSVファイルを用いた手作業でのデータ更新が行われがちです。この方法は初期コストを抑えやすい一方で、作業ミスや更新遅延が発生しやすいという弱点を抱えています。
特定の担当者が手順を把握している属人的な運用になると、担当者不在時に業務が滞るだけでなく、作業内容がブラックボックス化しやすくなります。その結果、データ品質の低下や業務継続リスクが高まる点が大きな課題です。
こうした手作業依存の背景には、技術的な制約を抱えたシステム構成が影響している場合も少なくありません。
旧システムにAPIがない
長年にわたって使われてきた基幹系のレガシーシステムでは、APIが提供されていないケースも多く見られます。この場合、ほかのシステムと直接データをやり取りすることが難しくなり、ファイル連携や中間サーバを介した複雑な構成を採用せざるを得ません。
その結果、連携処理が分かりにくくなり、障害発生時の原因特定や改修に時間がかかる傾向があります。システムの柔軟性が低下することで、新たなSaaS導入や業務改善のスピードを阻害する要因にもなります。
さらに、連携手法そのものが古いままでは、業務のリアルタイム性にも大きな影響を及ぼします。
リアルタイム連携ができない
夜間バッチ処理など、一定間隔でまとめてデータを連携する方式に依存している場合、データ反映に必ず時間差が生じます。在庫管理や顧客対応、経営モニタリングのように即時性が求められる業務では、このタイムラグが大きな問題になります。
最新の状況を把握できないまま判断を行うことで、機会損失や対応遅れにつながるリスクが高まります。リアルタイム性を前提とした業務や経営スタイルが広がる中で、こうした連携遅延は無視できない課題となっています
データ連携の主な手法と使い分け

データ連携を設計する際には、連携手法によって実現できることや運用のしやすさが大きく変わります。現在の企業システムは、基幹系からクラウドサービスまで多様化しており、一つの手法で全てをカバーするのは現実的ではありません。
そのため、代表的な手法の特徴を理解し、目的に応じて使い分ける視点が重要になります。
データ連携の三つの手法
データ連携の分野で代表的な手法として挙げられるのが、ETL/ELT、EAI、iPaaSの三つです。いずれもシステム間のデータをつなぐ役割を担いますが、想定している利用シーンや設計思想には明確な違いがあります。ここでは、それぞれの特徴を整理していきます。
ETL/ELT
ETLは、データを抽出し、変換し、蓄積するという流れを前提としたバッチ型のデータ連携手法です。主に基幹システムや業務システムから大量のデータを定期的に取得し、DWHなどの分析基盤へ集約する目的で利用されてきました。
近年では、先にデータをロードしてから変換処理を行うELTの考え方も一般化しており、クラウドDWHと組み合わせることで処理性能や拡張性を高めやすくなっています。分析やレポーティングを主目的としたデータ活用に向いた手法と言えます。
関連記事:ETLとは? - 概念・関連用語とツール活用のメリット・比較のポイントを解説
EAI
EAI(Enterprise Application Integration)は、システム同士を直接接続し、トランザクション単位で即時にデータを連携することを重視した手法です。受発注処理や在庫更新など、業務フローの中でリアルタイム性が求められる場面で強みを発揮します。
特にオンプレミス中心の環境や、基幹システム間を密接に連携させたいケースでは、EAIが採用されることが多く、業務処理の自動化や整合性確保に適した手法とされています。
iPaaS
iPaaS(Integration Platform as a Service)は、クラウド上で提供されるデータ連携基盤であり、SaaSやクラウドサービス同士を柔軟につなぐことを目的としています。あらかじめ用意されたコネクタやテンプレートを利用でき、ノーコードやローコードで設定できる点が特徴です。
短期間での導入が可能で、システム構成の変化にも対応しやすいため、クラウドやSaaSを前提とした環境では現実的かつ拡張性の高い選択肢となっています。
連携手法の違いと使い分け
これらの連携手法を選ぶ際には、更新頻度、データ量、そしてシステム構成を軸に考えることが有効です。
更新頻度が低く、扱うデータ量が多い場合には、ETLやELTのようなバッチ型連携が適しています。一方で、業務処理と連動して即時にデータを反映させる必要がある場合には、EAIやiPaaSが向いています。
また、オンプレミス中心のシステム構成ではEAIが馴染みやすく、クラウドやSaaS主体の環境ではiPaaSが柔軟性を発揮します。このように、手法そのものの特徴だけでなく、自社のIT環境や将来の拡張方針と整合するかどうかを踏まえて選定することが重要です。
関連記事:データ基盤とは何か? - 基礎知識から必要とされる理由・構築の流れ・ツールの設定について解説
データ統合とデータ連携の違い
データ統合は、連携されたデータを共通の形式や定義にまとめ、一貫性を持たせた状態で活用できるようにする考え方を指します。これに対して、データ連携は、異なるシステムやフォーマット間でデータを受け渡すためのプロセスそのものを意味します。
つまり、データ連携はデータ統合を実現するための前段階に位置づけられる概念であり、両者は目的と役割が異なります。連携の設計が不十分な場合、統合後のデータ品質や分析結果にも影響が及ぶため、それぞれを切り分けて理解した上で設計する視点が欠かせません。
関連記事:データ活用基盤とは?種類・導入メリット・成功ポイントを徹底解説
データ連携のメリット

データ連携は、単にシステム同士をつなぐための技術ではありません。分断されがちな企業内データを活かし、業務や経営の質を底上げするための重要な基盤です。
ここでは、データ連携によって企業が得られる代表的なメリットについて整理していきます。
全社データの一元化と可視化
データ連携を行うことで、部門ごとに個別管理されていた売上情報や顧客データ、業務実績などを横断的に把握できるようになります。これまで担当部門に確認しなければ見えなかった情報が、全社共通の視点で可視化されることで、経営層は状況を素早く把握し、根拠のある判断が可能になります。。
また、現場においても、自部門だけでなく他部門のデータや前後工程を踏まえた判断が可能になり、業務全体の最適化につながります。データが一元化されることで分析効率が向上し、レポート作成や会議準備にかかる時間の短縮といった効果も期待できます。
データ連携による可視化の効果は、日々の業務運用を支える面でも大きな価値を持ちます。
作業自動化と工数削減
従来、CSVファイルを使って行われていたデータ更新や転記作業は、多くの時間と手間を要するだけでなく、入力ミスや更新漏れといったリスクを伴っていました。データ連携を導入することで、これらの作業を自動化でき、担当者の負担を大幅に軽減することができます。
手作業が減ることで業務は標準化され、特定の担当者に依存しない運用が可能になります。その結果、業務品質のばらつきが抑えられ、安定した運用体制を構築しやすくなります。単なる省力化にとどまらず、人がより付加価値の高い業務に集中できる環境を整える点も、データ連携の大きなメリットです。
さらに、データ連携による自動化の効果は、スピードが求められる業務領域で一層際立ちます。
リアルタイムデータの活用
在庫管理やCRM、品質管理といった分野では、データの鮮度が業務成果に直結します。データ連携によって情報がリアルタイムに反映されるようになると、在庫不足や過剰在庫への迅速な対応、顧客対応の精度向上、不具合の早期検知といった効果が期待できます。
最新のデータを即座に活用できる環境は、意思決定のスピードを高めるだけでなく、市場や顧客の変化に柔軟に対応する力を企業にもたらします。その結果、競争力の強化や顧客満足度の向上につながる点も、データ連携が重視される理由の一つです。
自社に最適な連携方式の選び方

データ連携の手法には複数の選択肢がありますが、どれが最適かは企業の状況によって大きく異なります。流行している手法や他社の成功事例をそのまま当てはめても、自社の業務や体制に合わなければ期待した効果は得られません。
そのため、いくつかの判断軸に沿って、自社にとって現実的かつ持続可能な方式を見極めることが重要になります。
更新頻度・データ量で判断する
まず整理すべきなのが、どの程度の頻度で、どれだけの量のデータを連携する必要があるのかという点です。売上集計や分析用途のように日次や週次での更新で十分なケースと、在庫管理や業務処理のように秒単位での即時更新が求められるケースとでは、適した連携方式は異なります。
要件を明確にしないまま高頻度・リアルタイム連携を前提にすると、システム構成が過剰になり、コストや運用負荷が無駄に増える可能性があります。更新頻度とデータ量を整理することは、必要以上の投資を避けるための重要な第一歩です。
システム構成で判断する
企業のIT環境がオンプレミス中心なのか、クラウドやSaaSを主体としているのかによって、選ぶべき連携方式は変わります。特に近年は、オンプレミスとクラウドが混在するハイブリッド構成の企業も多く、複雑なシステム環境に柔軟に対応できるかどうかが重要な判断軸になります。
また、現時点の構成だけでなく、将来的なクラウド移行やSaaS活用の拡大を見据えた設計ができるかどうかも考慮する必要があります。短期的な最適化だけでなく、中長期のIT戦略と整合する連携方式を選ぶことが、結果的に運用の安定化につながります。
運用体制・スキルで判断する
データ連携は導入して終わりではなく、継続的な運用が前提となります。そのため、社内に専門的なエンジニアが常駐しているのか、あるいは現場部門が主導して設定や変更を行いたいのかによって、選択すべき方式は変わります。
高度なカスタマイズが可能なコードベースの連携は柔軟性が高い一方で、運用には専門知識が求められます。一方、ノーコードやローコードで設定できる仕組みであれば、IT部門に過度に依存せず、現場主導で改善を進めやすくなります。
自社のスキルレベルや運用体制に合った方式を選ぶことが、長期的な定着の鍵となります。
ガバナンス・セキュリティで判断する
データ連携では、複数のシステム間で重要な情報が行き交うため、権限管理やログ取得、セキュリティ対策が欠かせません。特に個人情報や機密データを扱う場合には、社内規定や法規制に対応できる仕組みであるかを事前に確認する必要があります。
アクセス制御が適切に行えるか、操作履歴を追跡できるか、監査やコンプライアンス要件を満たせるかといった点は、導入後に問題になりやすい要素です。技術的な利便性だけでなく、企業として守るべき基準を満たせるかどうかを含めて判断することが、安全で信頼性の高いデータ連携につながります。
データ連携導入の進め方

データ連携は、ツールを導入すれば自動的に成果が出るものではありません。事前準備から検証、運用までを段階的に進めることで、初めて業務や経営に価値をもたらします。
ここでは、多くの企業で実践されている導入プロセスを順を追って整理します。
プロセス①現状の棚卸しと要件定義
データ連携の第一歩は、現状を正確に把握することです。どのシステムにどのデータが存在し、誰が管理しているのか、そして更新頻度や利用目的は何かを整理します。この段階で曖昧なまま進めてしまうと、連携後に「想定と違う」「使えない」といった問題が発生しやすくなります。
現状の棚卸しを通じて、連携が本当に必要なデータと不要なデータを切り分け、業務や経営に直結する要件を明確にすることが、後工程の成否を大きく左右します。
要件が整理できたら、次は実装前にリスクを抑えるための検証フェーズに進みます。
プロセス②小さく始めるPoC
最初から全社規模でのデータ連携を目指すのは、リスクが高くおすすめできません。まずは特定の部門や業務に限定し、小規模なPoCを実施することで、技術的な実現性や運用上の課題を早期に洗い出します。
PoCを通じて、想定していたデータ連携が実際の業務フローに適しているか、運用負荷はどの程度かといった点を確認できます。この段階で得られた知見は、本格導入時の設計や体制づくりに大きく役立ちます。
検証と並行して、長期的な視点で欠かせないのがデータそのものの整備です。
プロセス③データ標準化
データ連携を進める前に、データ形式やマスタの定義を整えておくことは非常に重要です。例えば、同じ顧客のデータであっても、システムごとにIDや表記ルールが異なっていると、連携に不整合が発生しやすくなります。
事前に、データの粒度やコード体系を整理し、共通ルールを定めておくことで、連携後のトラブルを未然に防ぐことができます。この工程は地味に見えがちですが、後戻りのコストを抑えるためにも欠かせないステップです。
データの前提が整ったところで、具体的な仕組みづくりに進みます。
プロセス④ツール選定とアーキテクチャ設計
データ要件やデータ統合基盤を含めたアーキテクチャの特性を踏まえ、ETL、EAI、iPaaSといったデータ連携の選択肢の中から、自社に適したツールや方式を選定します。この際、現在のシステム構成だけでなく、将来的な拡張やクラウド活用の方針を考慮することが重要です。
短期的な導入のしやすさだけで判断すると、後から柔軟性や運用性に課題が生じる可能性があります。中長期の視点で、無理なく拡張できるアーキテクチャを設計することが、持続的な活用につながります。
関連記事:データウェアハウス構築完全ガイド:基本設計からクラウド比較・移行戦略・成功事例まで
プロセス⑤運用監視とガバナンス設計
データ連携の仕組みは導入して終わりではなく、改善し続けることではじめて価値を発揮します。そのため、エラー発生時にすぐ気づける監視体制や、誰がどのデータにアクセスできるかを管理する仕組みを整える必要があります。
ログ管理や権限設定を含めたガバナンスを設計しておくことで、トラブル時の原因特定が容易になり、セキュリティやコンプライアンス面でも安心して運用できます。データ連携の運用基盤を整えることが、データ連携を一過性の施策で終わらせず、企業の資産として定着させる鍵となります。
データ連携のユースケース
データ連携の効果を具体的に理解するために、ここでは株式会社TOAIの事例を紹介します。同社は、最適なデータ連携基盤を選定することで、顧客体験と経営成果の両立を実現しています。
株式会社TOAIにおけるデータ連携の事例
株式会社TOAIは、カラオケチェーン「ジャンカラ」やカラオケアプリ「UTAO」を展開し、「カラオケ体験価値10倍」というビジョンのもと、データ活用を経営の中核に据えています。その実現に向けて、インキュデータの支援を受けながら、段階的にデータ連携基盤の整備を進めました。
同社が抱えていた課題は、顧客データが部門やサービスごとに分断され、横断的な分析や施策設計が難しかった点にあります。そこでまず、公式アプリのUI/UX改善に取り組み、アプリログ解析を通じてデータに基づく改善サイクルを確立しました。
その後、サイロ化したデータを統合する基盤としてSnowflakeを選定しました。将来の拡張性や施策との親和性を重視した結果、柔軟にデータをつなげられる基盤としてSnowflakeが最適と判断されました。あわせて、MAツールとしてBrazeを導入し、顧客ごとのシナリオ設計やスピーディな施策実行が両立できる体制を構築しました。
これらの取り組みにより、「ジャンカラ」アプリの予約コンバージョン率は1ポイント向上し、年間約5万組の予約増加を実現しました。さらに、データ活用の内製化が進み、施策の精度と実行力の向上にもつながっています。
今後は、「ジャンカラ」と「UTAO」の相互送客やBIツールの導入を見据え、データ連携基盤を軸としたさらなる価値創出を目指しています。
「カラオケ体験価値10倍」を目指しデータ連携を進めデータ活用の取り組みを支援
https://www.incudata.co.jp/document/058.html
まとめ

データ連携は、単にシステム同士をつなぐための技術ではなく、企業の意思決定や業務の進め方そのものを支える重要な基盤です。部門やシステムごとに分断されていたデータをつなぐことで、全社的な視点で状況を把握できるようになり、判断のスピードと質の両方を高めることが可能になります。
ETL、EAI、iPaaSといった代表的な手法にはそれぞれ得意分野があり、どれが優れているかではなく、自社の目的やデータ特性、システム構成、運用体制に合っているかどうかが重要な判断軸になります。手法の違いを正しく理解し、無理のない選択を行うことで、データは実務や経営の中で価値を発揮します。
最初から大規模な連携を目指す必要はありません。小さな範囲から始め、効果や課題を確認しながら段階的に広げていくことで、データ分断を着実に解消していくことができます。
インキュデータは、Snowflake等を用いたモダンなデータ活用基盤構築から人材育成までワンストップで支援しています。
また、貴社のデータ活用度を診断し、活用方針を提案させていただくサービスも展開しております。データ活用を次のフェーズへ進めたい企業は、ぜひインキュデータにご相談ください。


データ活用の最前線セミナー


